
File Segmentation
![]()

Introducing File Segmentation
Each file in Alluxio has its own unique file ID. The file ID is used as the key to a worker selection algorithm that determines which worker should be responsible for caching the metadata and data of that file. The identical algorithm is implemented at the client side, so a client knows which worker it should go to fetch the cached file. The worker caches the file in its entirety, regardless of the size of the file. When reading the file, clients always go to the same worker, regardless of which part of the file they are trying to read.
This scheme works fine when the files stored in Alluxio are small to medium in size, compared to the capacity of a worker’s cache storage. A worker can easily handle a large number of such not-so-large files, and the worker selection algorithm will approximately distribute the files evenly onto different workers. However, in the case of very large files whose sizes are comparable to the cache capacity of a single worker, it becomes increasingly difficult to efficiently cache these huge files. If multiple clients request the same file, the one worker can easily be overloaded, throttling the overall read performance.
File segmentation is a feature of Alluxio that allows a huge file to be cached in multiple segments on multiple workers. The segment’s size is configurable by administrators and is usually significantly smaller than the file size. Segments of files can be efficiently served by multiple workers, reducing the possibility of worker load imbalance.
The following use cases may benefit from file segmentation:
- Storing very large files in Alluxio cache, where the files are larger than or close to a worker’s cache capacity
- High read performance applications that could benefit from multiple workers serving the same file
How File Segmentation Works
A segment of a file is defined by the file ID, along with its index within the file, as if the file is an ordered list of segments:
>
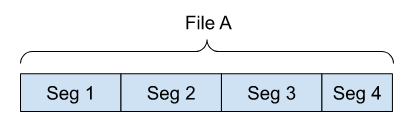
The segment ID of a segment is defined as a tuple containing the file ID and the segment index:
Segment ID := (fileId, segmentIndex)
When a client needs to locate the multiple parts of a segmented file, the segmented ID is used in place of the file ID as the key to the worker selection algorithm.
Reading a segmented file can be broken down into reading by segments sequentially. Given the following example file that consists of 4 segments:
>
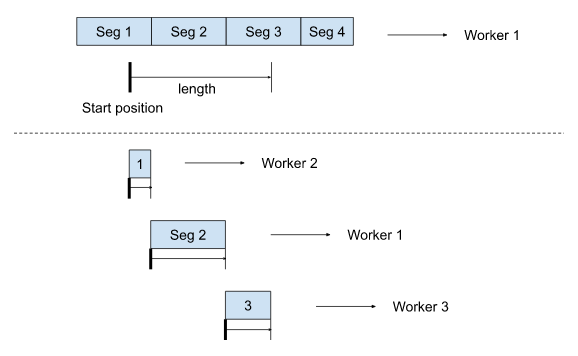
An unsegmented read that spans the region of 3 segments can be split into reads of 3 segments, and each segment will be served by different workers.
Limitations of File Segmentation
Currently, there are a few limitations with file segmentation:
- Files created and written directly by clients into Alluxio cannot be segmented
- Segment size is set cluster-wide and all nodes must share the same segment size. It cannot be set on a per-file basis.
Enabling File Segmentation
| Configuration item | Recommended value | Description |
|---|---|---|
alluxio.dora.file.segment.read.enabled |
true | Set to true to enable file segmentation. |
alluxio.dora.file.segment.size |
(depends on use case) | The size of the segments. Defaults to 1 GiB. |
Set alluxio.dora.file.segment.read.enabled to true on all nodes of Alluxio, including clients.
Set alluxio.dora.file.segment.size to a desired segment size; this value should also be consistent across all nodes.
The best segment size can be determined by considering the following factors:
- Different segments are likely mapped to different workers. When reading a file sequentially, a client needs to switch among different workers to read the different segments. If the size of the segments is too small, the client will have to frequently switch between workers and suffer from underutilized network bandwidth.
- The data of a segment is stored in its entirety in a single worker. If the segment size is too large, the chance of uneven cache usage on different workers will increase.
The best segment size achieves a compromise between the performance and the even distribution of cached data. A common range for segment size varies between several gigabytes to tens of gigabytes.